
Un extenso estudio realizado por el Tow Center for Digital Journalism ha revelado serias deficiencias en cómo los principales motores de búsqueda impulsados por inteligencia artificial citan y atribuyen contenido periodístico. La investigación, que evaluó ocho herramientas de búsqueda generativa con capacidades de búsqueda en tiempo real, encontró que estos sistemas no solo proporcionan información incorrecta con alarmante frecuencia, sino que lo hacen con una confianza injustificada que podría engañar fácilmente a los usuarios. Los hallazgos plantean preocupaciones significativas tanto para las empresas de medios como para los consumidores de información, sugiriendo que incluso los acuerdos formales de licencia entre compañías de IA y editores no garantizan una atribución precisa.
Consecuencias para el periodismo
La popularidad de las herramientas de búsqueda con inteligencia artificial está creciendo rápidamente. Según el artículo del Tow Center, “casi uno de cada cuatro estadounidenses afirma haber utilizado IA en lugar de motores de búsqueda tradicionales”. Este cambio representa un desafío fundamental para la industria periodística, ya que estos sistemas obtienen su valor al rastrear internet en busca de información actualizada y relevante, contenido que a menudo es producido por medios de comunicación.
La diferencia crucial entre los motores de búsqueda tradicionales y las herramientas generativas radica en cómo presentan la información. Mientras que los buscadores convencionales funcionan como intermediarios que dirigen a los usuarios hacia sitios web de noticias y otros contenidos de calidad, las herramientas de búsqueda generativa procesan y reempaquetan la información por sí mismas, interrumpiendo el flujo de tráfico hacia las fuentes originales.
“Se ha producido un desequilibrio preocupante”, señala el informe publicado por el Centro Tow para el Periodismo Digital de la Universidad de Columbia. “Las respuestas conversacionales de estos chatbots a menudo ocultan serios problemas subyacentes con la calidad de la información”. Esta situación ha creado una urgente necesidad de evaluar cómo estos sistemas acceden, presentan y citan el contenido periodístico.
El estudio sigue la línea de investigaciones anteriores del Tow Center y demuestra que los problemas identificados no son exclusivos de un solo chatbot, sino que persisten en todas las principales herramientas de búsqueda generativa probadas.
Confianza excesiva en respuestas incorrectas
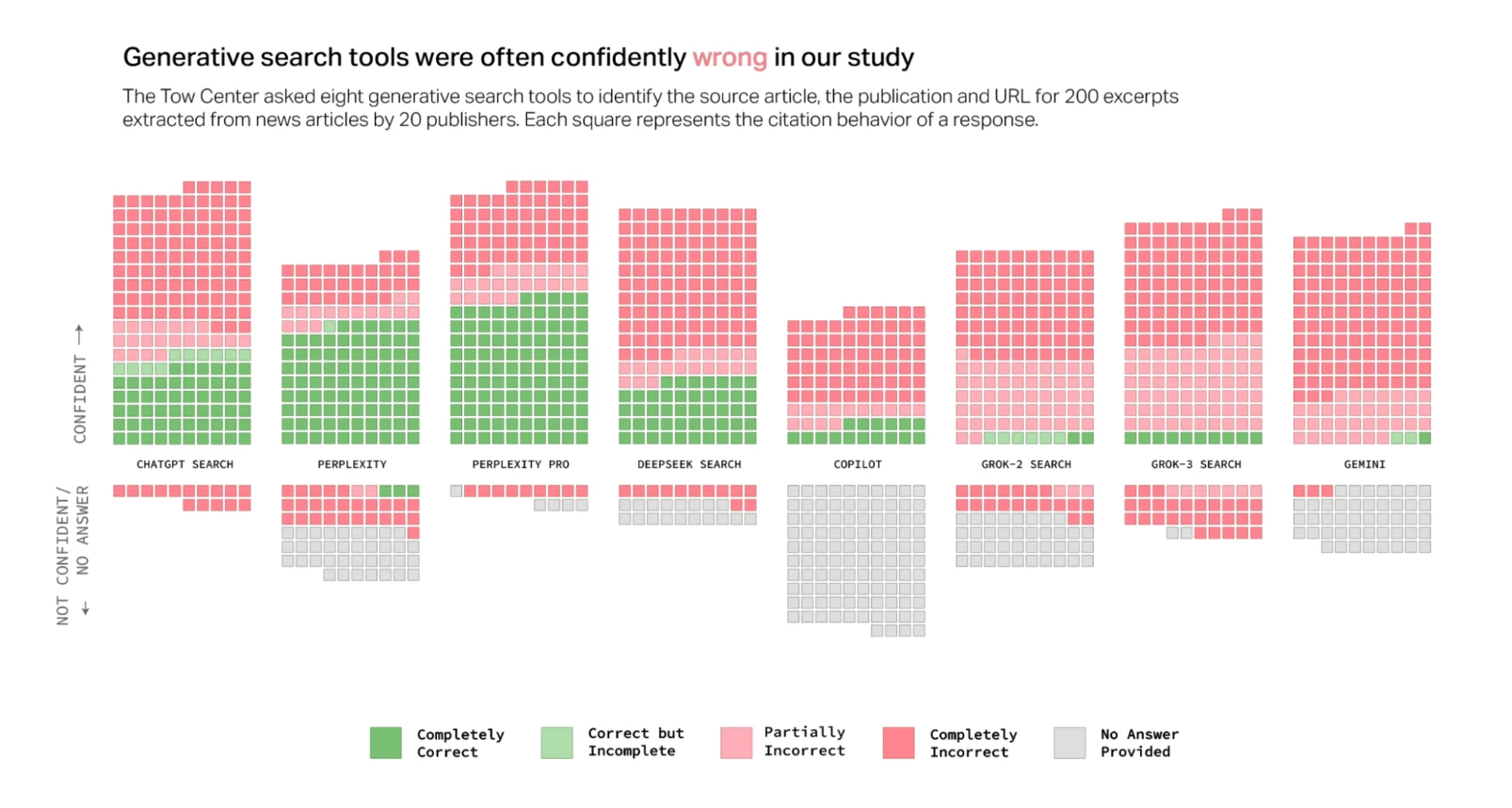
La metodología del estudio fue rigurosa: los investigadores seleccionaron aleatoriamente diez artículos de cada editor, extrajeron manualmente fragmentos directos de esos artículos y solicitaron a cada chatbot que identificara el titular del artículo correspondiente, el editor original, la fecha de publicación y la URL. Los fragmentos elegidos fueron aquellos que, al ser introducidos en Google, devolvían la fuente original entre los tres primeros resultados.
Los resultados fueron sorprendentes: colectivamente, los chatbots proporcionaron respuestas incorrectas a más del 60 % de las consultas. La tasa de error varió considerablemente entre plataformas, con Perplexity respondiendo incorrectamente al 37 % de las consultas, mientras que Grok 3 tuvo una tasa de error mucho mayor, respondiendo incorrectamente al 94 % de las consultas.
“La mayoría de las herramientas que probamos presentaron respuestas inexactas con una confianza alarmante”, revela el estudio del Tow Center, señalando que rara vez utilizaron frases calificativas como “parece”, “es posible” o “podría”, o reconocieron lagunas de conocimiento con declaraciones como “no pude localizar el artículo exacto”.
El caso de ChatGPT resulta particularmente ilustrativo: identificó incorrectamente 134 artículos, pero señaló falta de confianza solo quince veces de sus doscientas respuestas, y nunca se negó a proporcionar una respuesta. Con la excepción de Copilot, que rechazó más preguntas de las que respondió, todas las herramientas fueron consistentemente más propensas a proporcionar una respuesta incorrecta que a reconocer sus limitaciones.
“Estos chatbots están en esencia creando un nuevo problema de desinformación mientras pretenden resolver otro”, advirtió Chirag Shah, experto en sistemas de información citado en el informe. “El tono autoritario con que presentan información errónea hace casi imposible para el usuario promedio detectar cuándo están siendo engañados”.
La siguiente tabla resume los resultados mostrados en el estudio, indicando el nivel de precisión de cada herramienta:
| Herramienta | Completamente correcto | Correcto pero incompleto | Parcialmente incorrecto | Completamente incorrecto | Sin respuesta |
|---|---|---|---|---|---|
| ChatGPT Search | Bajo | Bajo | Moderado | Alto | Bajo |
| Perplexity | Moderado | Bajo | Moderado | Moderado | Bajo |
| Perplexity Pro | Moderado | Bajo | Alto | Alto | Bajo |
| DeepSeek Search | Moderado | Bajo | Alto | Alto | Bajo |
| Copilot | Bajo | Bajo | Moderado | Alto | Alto |
| Grok-2 Search | Bajo | Bajo | Alto | Alto | Moderado |
| Grok-3 Search | Bajo | Bajo | Alto | Alto | Moderado |
| Gemini | Bajo | Bajo | Alto | Alto | Moderado |
- Perplexity (versión estándar) tuvo el mejor desempeño general, con niveles moderados tanto de respuestas completamente correctas como de respuestas completamente incorrectas.
- Perplexity Pro y DeepSeek Search mostraron un nivel moderado de respuestas completamente correctas, pero también altos niveles de respuestas incorrectas.
- Copilot fue la herramienta que más frecuentemente se abstuvo de proporcionar una respuesta (categoría “Sin Respuesta”).
- Todas las herramientas tuvieron un nivel bajo de respuestas en la categoría “Correcto pero Incompleto”.
- La mayoría de las herramientas (6 de 8) mostraron niveles altos de respuestas completamente incorrectas, lo que confirma el título del gráfico: las herramientas de búsqueda generativa a menudo estaban confiadamente equivocadas.
Modelos premium vs. gratuitos
Una revelación contraintuitiva del estudio es que los modelos premium, como Perplexity Pro (20 dólares mensuales) o Grok 3 (40 dólares mensuales), que podrían presumirse más confiables dado su costo y sus supuestas ventajas computacionales, presentaron comportamientos problemáticos específicos.
“Nuestras pruebas mostraron que, si bien ambos respondieron más consultas correctamente que sus equivalentes gratuitos correspondientes, paradójicamente también demostraron tasas de error más altas”, indica el estudio del Tow Center2. Esta contradicción surge principalmente de su tendencia a proporcionar respuestas definitivas pero incorrectas, en lugar de negarse a responder directamente a la pregunta.
La preocupación fundamental va más allá de los errores factuales de los chatbots, extendiéndose a su tono conversacional autoritario, que puede dificultar que los usuarios distingan entre información precisa e imprecisa. Esta confianza inmerecida presenta a los usuarios una ilusión potencialmente peligrosa de fiabilidad y precisión.
En una entrevista concedida a los investigadores, Mark Howard, director de operaciones de Time, expresó que “si alguien como consumidor está creyendo ahora mismo que cualquiera de estos productos gratuitos va a ser 100% preciso, entonces vergüenza debería darles”. Su comentario refleja una realidad incómoda: incluso los modelos más avanzados están lejos de la infalibilidad que su presentación sugiere.
El ‘disallow’ en el archivo robots.txt no funciona bien
El estudio también reveló inconsistencias significativas en cómo los chatbots respetan las preferencias de exclusión de los medios de comunicación. Cinco de los ocho chatbots probados (ChatGPT, Perplexity y Perplexity Pro, Copilot y Gemini) han hecho públicos los nombres de sus rastreadores, dando a los medios de comunicación la opción de bloquearlos, mientras que los rastreadores utilizados por los otros tres (DeepSeek, Grok 2 y Grok 3) no son conocidos públicamente. Esto se puede lograr a través del archivo robots.txt.
“Esperábamos que los chatbots respondieran correctamente a consultas relacionadas con medios de comunicación a cuyos rastreadores tenían acceso, y se negaran a responder consultas relacionadas con sitios web que habían bloqueado el acceso a su contenido”, explica el informe. “Sin embargo, en la práctica, eso no es lo que observamos”.
En particular, ChatGPT, Perplexity y Perplexity Pro exhibieron comportamientos inesperados dado lo que sabemos sobre qué medios de comunicación permiten acceso a sus rastreadores. En algunas ocasiones, los chatbots respondieron incorrectamente o se negaron a responder consultas de medios de comunicación que les permitían acceder a su contenido. Por otro lado, a veces respondieron correctamente a consultas sobre medios de comunicación a cuyo contenido no deberían haber tenido acceso.
El caso más flagrante fue Perplexity Pro, que identificó correctamente casi un tercio de los noventa extractos de artículos a los que no debería haber tenido acceso. Sorprendentemente, la versión gratuita de Perplexity identificó correctamente los diez extractos de artículos con paywall que compartieron de National Geographic, a pesar de que el sitio web ha prohibido los rastreadores de Perplexity y no tiene una relación formal con la empresa de IA.
“Aunque existen otros medios a través de los cuales los chatbots podrían obtener información sobre contenido restringido, este hallazgo sugiere que Perplexity, a pesar de afirmar que ‘respeta las directivas robots.txt’, puede haber ignorado las preferencias de rastreador de National Geographic”, señala el estudio. El desarrollador Robb Knight y la revista Wired informaron evidencias de que Perplexity ignoraba el Protocolo de Exclusión de Robots el año pasado. De manera similar, Press Gazette informó este mes que el New York Times, a pesar de bloquear el rastreador de Perplexity, fue el sitio de noticias más referido por el chatbot en enero, con 146.000 visitas.
Danielle Coffey, presidenta de la News Media Alliance, escribió en una carta a los editores en junio pasado que “sin la capacidad de optar por no participar en el raspado masivo, no podemos monetizar nuestro valioso contenido y pagar a los periodistas. Esto podría dañar seriamente a nuestra industria”. Sus palabras subrayan la gravedad del problema para la sostenibilidad del periodismo de calidad.
Enlaces falsos y citación errónea
Uno de los hallazgos más preocupantes del estudio fue la tendencia generalizada de las herramientas de búsqueda generativa a citar artículos incorrectos. Por ejemplo, DeepSeek atribuyó erróneamente la fuente de los extractos proporcionados en las consultas 115 de 200 veces. Esto significa que el contenido de los editores de noticias frecuentemente se atribuía a la fuente equivocada.
“Incluso cuando los chatbots parecían identificar correctamente el artículo, a menudo no lograban vincular adecuadamente a la fuente original”, señala el estudio. Esto crea un problema doble: los editores que desean visibilidad en los resultados de búsqueda no la obtienen, mientras que el contenido de aquellos que desean optar por no participar sigue siendo visible contra su voluntad.
En algunas ocasiones, los chatbots dirigían a versiones sindicadas de artículos en plataformas como Yahoo News o AOL en lugar de las fuentes originales, incluso cuando se sabía que el editor tenía un acuerdo de licencia con la empresa de IA. Por ejemplo, a pesar de su asociación con el Texas Tribune, Perplexity Pro citó versiones sindicadas de artículos del Tribune para tres de las diez consultas, mientras que Perplexity citó una versión republicada no oficial para una. Esta tendencia priva a las fuentes originales de la atribución adecuada y del potencial tráfico de referencia.
Por otro lado, las versiones sindicadas o copias no autorizadas de artículos de noticias presentan un desafío para los editores que desean excluirse del rastreo. Su contenido seguía apareciendo en los resultados sin su consentimiento, aunque incorrectamente atribuido a las fuentes que lo republicaron. Por ejemplo, mientras USA Today bloquea el rastreador de ChatGPT, el chatbot seguía citando una versión de su artículo que fue republicada por Yahoo News.
Más alarmante aún, la tendencia de las herramientas de búsqueda generativa a fabricar URLs también puede afectar la capacidad de los usuarios para verificar las fuentes de información. Grok 2, por ejemplo, tendía a vincular a la página principal del medio de publicación en lugar de a artículos específicos.
“Más de la mitad de las respuestas de Gemini y Grok 3 citaron URLs fabricadas o rotas que conducían a páginas de error”, revela el estudio. “De las 200 consultas que probamos para Grok 3, 154 citas llevaron a páginas de error. Incluso cuando Grok identificaba correctamente un artículo, a menudo vinculaba a una URL fabricada”.
Acuerdos de licencia sin garantías
Entre las empresas cuyos modelos fueron probados, OpenAI y Perplexity han expresado el mayor interés en establecer relaciones formales con portales de noticias. En febrero, OpenAI aseguró sus decimosexto y decimoséptimo acuerdos de licencia de contenido de noticias con los grupos de medios Schibsted y Guardian, respectivamente. De manera similar, el año pasado Perplexity estableció su propio Programa de Editores, “diseñado para promover el éxito colectivo”, que incluye un acuerdo de reparto de ingresos con los medios de comunicación participantes.
Un acuerdo entre empresas de IA y editores a menudo implica el establecimiento de un conducto de contenido estructurado regido por acuerdos contractuales e integraciones técnicas. Estos arreglos típicamente proporcionan a las empresas de IA acceso directo al contenido del editor, eliminando la necesidad de rastrear sitios web. Tales acuerdos podrían generar la expectativa de que las consultas de usuarios relacionadas con contenido producido por editores asociados producirían resultados más precisos. Sin embargo, esto no fue lo que observaron durante las pruebas realizadas en febrero de 2025.
“Observamos una amplia gama de precisión en las respuestas a consultas relacionadas con editores asociados”, indica el estudio. Time, por ejemplo, tiene acuerdos tanto con OpenAI como con Perplexity, y aunque ninguno de los modelos asociados con esas empresas identificó su contenido correctamente el 100% del tiempo, se encontraba entre los editores más precisamente identificados en el conjunto de datos.
Por otro lado, el San Francisco Chronicle permite el rastreador de búsqueda de OpenAI y es parte de la “asociación estratégica de contenido” de Hearst con la empresa, pero ChatGPT solo identificó correctamente uno de los diez extractos que compartieron del medio de comunicación. Incluso en esa única instancia, el chatbot nombró correctamente al editor pero no proporcionó una URL.
Cuando los investigadores preguntaron si las empresas de IA asumían algún compromiso para garantizar que el contenido de los editores asociados se mostrara con precisión en sus resultados de búsqueda, Mark Howard de Time confirmó que esa era la intención. Sin embargo, añadió que las empresas no se comprometían a ser 100% precisas.
Conclusiones
Los hallazgos de este estudio se alinean estrechamente con los descritos en un estudio anterior sobre ChatGPT, publicado en noviembre de 2024, que revelaba patrones consistentes en los chatbots: presentaciones confiadas de información incorrecta, atribuciones engañosas a contenido sindicado y prácticas inconsistentes de recuperación de información.
Críticos de la búsqueda generativa como Chirag Shah y Emily M. Bender han planteado preocupaciones sustanciales sobre el uso de modelos de lenguaje grandes para la búsqueda, señalando que “quitan transparencia y agencia al usuario, amplifican aún más los problemas asociados con el sesgo en los sistemas de acceso a la información, y a menudo proporcionan respuestas sin fundamento y/o tóxicas que pueden pasar desapercibidas para un usuario típico”.
Estos problemas plantean un daño potencial tanto para productores como para consumidores de noticias. Muchas de las empresas de IA que desarrollan estas herramientas no han expresado públicamente interés en trabajar con editores de noticias. Incluso aquellas que lo han hecho a menudo no logran producir citas precisas o honrar preferencias indicadas a través del Protocolo de Exclusión de Robots. Como resultado, los editores tienen opciones limitadas para controlar si su contenido es mostrado por chatbots y cómo, y esas opciones parecen tener una eficacia limitada.
A pesar de esto, Howard, el director de operaciones de Time, mantiene optimismo sobre futuras mejoras: “Tengo una línea internamente que digo cada vez que alguien me trae algo sobre cualquiera de estas plataformas, mi respuesta es: ‘Hoy es lo peor que el producto jamás será’. Con el tamaño de los equipos de ingeniería, el tamaño de las inversiones en ingeniería, creo que simplemente va a seguir mejorando”.
El estudio contactó a todas las empresas de IA mencionadas en este informe para obtener comentarios, y solo OpenAI y Microsoft respondieron, aunque ninguna abordó los hallazgos o preguntas específicas. OpenAI envió una declaración casi idéntica a su comentario sobre el estudio anterior, mientras que Microsoft afirmó que “respeta el estándar robots.txt y honra las instrucciones proporcionadas por los sitios web que no desean que el contenido en sus páginas sea utilizado con los modelos de IA generativa de la empresa”.
Para los consumidores de noticias, estos hallazgos subrayan la importancia de mantener un escepticismo saludable hacia las respuestas proporcionadas por herramientas de búsqueda con IA, especialmente cuando presentan información con confianza absoluta. Para los editores de noticias, plantean preguntas difíciles sobre cómo proteger su contenido y asegurar una atribución adecuada en un ecosistema de información en rápida evolución.
La batalla por la integridad de la información parece estar lejos de resolverse, con consecuencias significativas tanto para el futuro del periodismo como para la calidad de la información disponible para el público.